 | ||
 |  | |
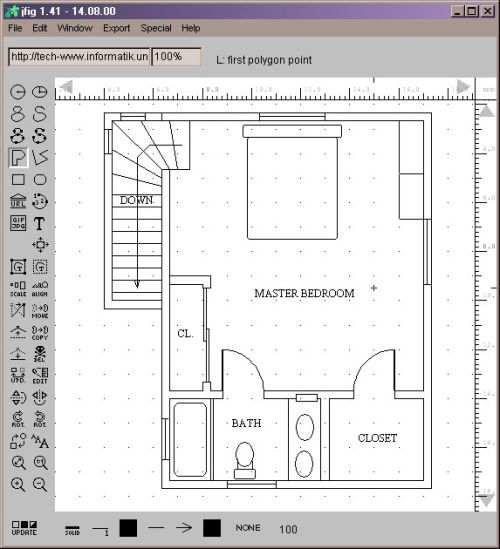
| An example of using cross-modal learning to map speech onto interface actions. The jfig drawing program has been instrumented so that all Java events can be detected and associated with speech events. In the video Peter "delegates" some of the operations from the mouse to the speech channel. There is no explicit training phase. Instead, the interface watches and listens to Peter and learns during use. | |
| mpg video (28M) | |
 |
|
Related papers:
Peter Gorniak and Deb Roy. Augmenting User Interfaces with Adaptive Speech Commands. To appear in Proceedings of ICMI 2003. pdf (355K) |
|
This material is based upon work supported by the National Science Foundation under Grant No. 0083032. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. |
|
