Presented at the AAAI 1995 Spring Symposium Series: Empirical Methods
in Discourse Interpretation and Generation. March 27-29, Stanford University.
A Discourse Analysis Approach to
Structured Speech
Lisa J. Stifelman
MIT Media Laboratory
20 Ames Street E15-352
Cambridge, MA 02139
lisa@media.mit.edu
Abstract
Given a recording of a lecture, one cannot easily locate a topic of interest,
or skim for important points. However, by presenting the user with a summary
of a discourse, listening to speech can be made more efficient. One approach
to the problem of summarizing and skimming speech has been termed "emphasis
detection." This study evaluates an emphasis detection approach by
comparing the speech segments selected by the algorithm with a hierarchical
segmentation of a discourse sample (based on [Grosz & Sidner 1986]).
The results show that a high percentage of segments selected by the algorithm
correspond to discourse boundaries, in particular, segment beginnings in
the discourse structure. Further analysis is needed to identify cues that
distinguish the hierarchical structure. The ultimate goal is to determine
whether it is feasible to "outline" speech recordings using intonational
and limited text-based analyses.
Introduction
Researchers are currently attempting to determine ways of finding structure
in [Grosz & Hirschberg 1992] [Hawley 1993] , summarizing [Chen &
Withgott 1992] , and skimming [Arons 1994a] speech and sound. Speech is
slow, serial, and difficult to manage--given a recording of a lecture, one
cannot easily locate a topic of interest, or skim for important points.
We are forced to receive information sequentially, limited by the talker's
speaking rate rather than our listening capacity. By presenting the user
with a summary or overview of the discourse, listening to speech can be
made more efficient.
One approach to the problem of summarizing and skimming speech has been
termed "emphasis detection" [Chen & Withgott 1992] . This
approach uses prosodic cues (e.g., pitch, energy) for finding "emphasized"
portions of audio recordings. Chen and Withgott [Chen & Withgott 1992]
use speech labeled by subjects for emphasis to train a Hidden Markov Model.
Arons [Arons 1994a] performs a direct analysis of the speech data rather
than using a train and test technique. In both cases the final result is
a selection of emphasized segments--indices into the speech corresponding
to the most "salient" portions. A limitation of this work is that
the structure of the speech is not identified--while salient segments are
determined, the relationships among them are not.
This study evaluates Arons' emphasis detection approach by comparing the
speech segments selected by the algorithm with a hierarchical segmentation
of the discourse (based on [Grosz & Sidner 1986] ). By incorporating
knowledge about discourse structure, speech summarization work can be expanded
in two significant ways. First, techniques are needed for determining the
structure and relationships among speech segments identified as salient.
Secondly, better methods can be developed for determining the validity of
the results. Currently, evaluation is difficult since there is a lack of
a clear definition of "emphasis" or what constitutes a good audio
summary. Discourse structure provides a foundation upon which emphasis detection
and structure recognition algorithms can be evaluated.
Method
Subjects
A single discourse sample was segmented by two people according to instructions
devised by Grosz and Hirschberg [Grosz & Hirschberg 1992] . Both segmenters
were experienced at labeling discourses using these instructions.
Discourse Sample
The discourse sample is a 13 minute talk by a single speaker about his interests
and current research. The talk is not interactive--he is only interrupted
twice to answer brief clarification questions.
Manual Discourse Segmentation
Two subjects labeled the starting and ending points of discourse segments,
as well as the hierarchical structure of the discourse. Figure 1 shows a
portion of the final segmentation. An open bracket (e.g., [1) indicates
when a new segment is introduced, and a closed bracket when it is completed
(e.g., ]1). The hierarchical structure (i.e., when one segment is
embedded inside another) is indicated by the numbering and indentation.
[1
[1.1
1. Well my name's Jim Smith
2. but whenever I write it it comes out James for some reason but
3. I don't care what you call me.
]1.1
[1.2
4. um I'm uh I'm currently at the Kalamazoo Computer Science
Laboratory
5. I've been at Kalamazoo for a long time aside from about a nine month
break
6. um I've been there and gotten my my bachelor's my master's
7. um something called an engineer's degree
8. which pretty much makes me a Ph.D. student er otherwise I'd have to leave.
]1.2
[1.3
9. um I work for a uh networking group
10. and I'm sort of a special person in the group because I'm not really
what they do
11. except that I'm supposed to be driving their need for this um high-speed
ne network
[1.3.1
12. um and I work for Professor Schmidt which I mention here
because he came out
13. and and a lot of you got to hear what he had to say
14. and I might repeat a little bit of that
]1.3.1
15. My interests are in speech processing and recognition for uh multimedia
applications
16. and again that from my group's perspective they're interested in me
as someone who who gives a reason for their for their network.
]1.3
]1
Figure 1: A portion of the manual discourse segmentation.
[1]
Initially, the two labelers segmented the discourse using a text transcript
only. The two segmentations were then compared, discussed, and argued over
until a single result was decided upon. Next, each labeler made modifications
to the initial text-based segmentation while listening to an audio recording
of the sample. There were no time constraints--the labelers were allowed
to listen to the material as many times as needed. The two labelers first
worked separately and then together to agree on a final segmentation.
Automatic Analysis--Arons' Emphasis Detection Algorithm
Following the human labeling of the discourse structure, Arons' emphasis
detection algorithm was used to segment the discourse sample. The algorithm
identifies time points in the sound file marking the beginning of "emphasized"
portions of speech. For the discourse sample used in this study the algorithm
selected 22 segments.
The Arons emphasis detection algorithm performs a direct analysis of the
pitch patterns of a discourse. The following is a step-by-step description
of the algorithm [Arons 1994b] :
- Create a histogram of pitch values in the signal (F0 in Hz versus
percentage of frames, where a frame is 10 ms long).
- Define an "emphasis threshold" to select the top 1% of the
pitch frames.
- Calculate "pitch activity" scores over 1 second windows.
The pitch activity score equals the number of frames above the emphasis
threshold (determined in step 2).
- Combine the scores of nearby regions (within an 8 second range).
- Select regions with a pitch activity score greater than zero.[2]
Results
Discourse Segmentation Analysis
All utterances in the discourse are divided into the following five categories
as defined by Grosz and Hirschberg [Grosz & Hirschberg 1992] :
- Segment initial sister (SIS) - The utterance beginning a new discourse
segment that is introduced as the previous one is completed (e.g., Figure
1 utterance 4).
- Segment initial embedded (SIE) - The utterance beginning a new discourse
segment that is a subcomponent of the previous one (e.g., utterance 12).
- Segment medial (SM) - An utterance in the middle of a discourse segment
(e.g., utterances 5-7).
- Segment medial pop (SMP) - The first utterance continuing a discourse
segment after a subsegment is completed (e.g., utterance 15).
- Segment final (SF) - The last utterance in a discourse segment (e.g.,
utterance 3).
The first two categories, SIS and SIE, are combined into a single category
of segment beginning utterances (SBEG). SBEG, SMP, and SF utterances are
all considered discourse segment boundaries.
Emphasis Detection versus Discourse Structure
The Arons emphasis detection algorithm was written with the goal of "finding
important or emphasized portions of a recording, and locating the equivalent
of paragraphs or new topic boundaries for the sake of creating audio overviews
or outlines" ( [Arons 1994a] , p. 107). Note that the algorithm was
not explicitly designed with any theory of discourse structure in mind.
It is important to distinguish "finding salient portions" of a
discourse from "finding structure." While there may be a strong
correlation between the beginning of new segments (i.e., the introduction
of new topics) and the most salient portions of a discourse, there is nothing
to prevent these salient "sound bytes" from occurring in the middle
of a discourse segment. Ayers [Ayers 1994] found that the introductory phrases
of discourse segments sometimes had a lower pitch range in comparison to
the following more "content-rich phrases."
The analysis described in this paper concentrates on topic (i.e., segment)
boundaries which may or may not correspond to the most salient content of
the discourse. However, as these boundaries are fundamental to the structure
of the discourse, they will be critical for allowing users to navigate and
locate portions of the audio that they believe to be salient.
Comparison Calculations
In order to evaluate the correlation between the algorithm and discourse
structure, basic signal detection metrics are employed. The number of hits,
misses, false alarms, and correct rejections are calculated. For example,
in calculating the number of segment beginning utterances found by the algorithm,
a "hit" is defined as an index that falls anywhere within the
intonational phrase of an SBEG utterance. The discourse was divided into
intonational phrases (i.e., major phrase boundaries) according to Pierrehumbert's
theory of English intonation [Pierrehumbert 1975, Pierrehumbert & Hirschberg
1990] and the TOBI labeling system [Silverman et al. 1992] .
In an analysis similar to one performed by Passonneau and Litman [Passonneau
& Litman 1993] , four performance metrics are calculated: percent recall,
precision, fallout, and error (Figure 2). Recall is equivalent to the percent
correct identification of a particular feature while precision takes into
account the proportion of false alarms. It is important to calculate both
recall and precision metrics. For example, if the emphasis detection algorithm
were simply to identify every phrase in the discourse as a segment beginning,
the recall would be 100% but the precision would be considerably lower (e.g.,
if there are 10 SBEGs and 100 utterances total, the precision would be only
10%). Alternatively if the algorithm selected only 1 segment beginning but
made no false alarms, the precision would be 100% and the recall considerably
lower.
Recall H / (H + M)
Precision H / (H + FA)
Fallout FA / (FA + CR)
Error (FA + M) / (H + FA + M + CR)
Figure 2: Evaluation metrics. H = Hits, M = Misses, FA = False Alarms, CR
= Correct Rejections.
Comparison by Discourse Category
The twenty two indices selected by the algorithm were compared to the discourse
segmentation (Figures 3-6). The number of indices corresponding (i.e., within
the same intonational phrase) to each of the five categories of utterances
in the discourse were calculated.
Eighteen out of the 22 indices selected by the algorithm correspond to segment
boundaries of some kind (precision = 82%). In addition, 15 of the 22 indices
correspond to SBEG utterances (precision = 68%[3]).
Note that Grosz and Hirschberg [Grosz & Hirschberg 1992] considered
SBEG utterances alone, and SBEG plus SMP utterances in their analysis. SBEG
and SMP utterances together constitute a broader class of discourse segment
shifts. The precision for finding segment shifts is higher (77%) than for
SBEGs alone (68%).
Category # Hits Total in Sample
SIS 9 15
SIE 6 28
SMP 2 7
SF 1 23
SM 4 124
Totals 22 197
Figure 3: Correspondence between algorithm indices and discourse structure
categories.
Discourse Discourse
Boundary Non-Boundary
Algorithm 18 4
Boundary
Algorithm 55 120
Non-Boundary
Figure 4: Correspondence between algorithm indices and segment boundaries
(SBEG, SMP, or SF). Hits = 18, Misses = 55, False Alarms = 4, Correct Rejections
= 120.
Discourse Discourse
SBEG Non-SBEG
Algorithm 15 7
SBEG
Algorithm 28 147
Non-SBEG
Figure 5: Correspondence between algorithm indices and segment beginnings
(SBEG).
Recall Precision Fallout Error
SBEG 0.35 0.68 0.05 0.18
Boundary 0.25 0.82 0.03 0.30
Figure 6: Evaluation metrics across segment beginnings and across all segment
boundaries.
Comparison by Segment Level
The utterances in the discourse are also classified by "segment level"--the
absolute number of levels embedded in the hierarchical discourse structure
(Figures 7-8). In this discourse sample, utterances occur at level 0 (the
outermost level of the discourse) through 7 (the innermost level). The algorithm
selects an equal number of segment beginning utterances at several different
levels of embedding in the discourse structure.
Level Algorithm Discourse Total in
SBEG SBEG Sample
0 0 0 2
1 0 0 1
2 4 7 34
3 4 9 42
4 4 10 56
5 2 8 34
6 1 5 20
7 0 4 8
Figure 7: Break-down by segment level of algorithm indices matching SBEG
utterances, the number of SBEGs at each level, and the total number of utterances
at each level.
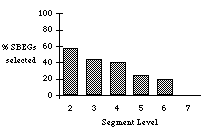
Figure 8: The percent of SBEGs selected by the algorithm out of the number
of SBEGs in the discourse at each level (Algorithm SBEG / Discourse SBEG).
Figure 9 shows the results for two different criteria levels--an index selected
by the algorithm is considered a "hit" if its level in the structure
is less than or equal to the criteria level. These criteria have been selected
to correspond to the objective of finding the major topics in the discourse.
Given the less stringent criteria (level <= 4) the algorithm's precision
for SBEG utterances increases from 53% to 80%.
Level <= 3 Recall Precision Fallout Error
SBEG 0.50 0.53 0.26 0.35
Boundary 0.31 0.50 0.20 0.40
Level <= 4 Recall Precision Fallout Error
SBEG 0.46 0.80 0.18 0.40
Boundary 0.30 0.78 0.15 0.49
Figure 9: Evaluation metrics for Level <= 3 and Level <= 4
criteria across SBEGs and boundaries.
Discussion
Comparison by Discourse Category
An objective of Arons' algorithm is to locate new topic boundaries. A high
percentage of indices selected by the algorithm correspond to segment boundaries,
in particular segment beginnings. The algorithm's precision for finding
segment boundaries and beginnings is relatively high while the recall is
low. By design, the algorithm selects only a small number of segments in
order to achieve a maximum amount of "time-compression." This
causes the percent recall to be low. The goal is to provide the listener
with a fast overview, so not all segments are presented.
These findings are in contrast to the results found by Passonneau and Litman
[Passonneau & Litman 1993] using a simple pause-based algorithm to detect
segment boundaries. This pause-based algorithm[4]
achieved a high recall but low precision score--it detected a high percentage
of segment boundaries but also had a high percentage of false alarms. This
algorithm had 92% recall and 18% precision for segment boundaries, while
the Arons algorithm achieves 25% recall and 82% precision. In addition,
the Arons algorithm has lower fallout and error--3% and 30% versus 54% and
49%. It is important to note that Passonneau and Litman's pause-based algorithm
was tested on 10 different narratives, while these results are for a single
discourse. Passonneau and Litman also determine segment boundary strength
based on the degree of agreement between seven segmenters.
Comparison by Segment Level
Since segment beginnings represent the points in the discourse where new
topics and subtopics are introduced, these utterances are appropriate for
use in a summary of an audio recording. However, for maximum time savings,
only the "major" topic introductions should be presented.
The comparison by segment level reveals an area for improving the algorithm.
Currently, the algorithm selects a number of segment beginning utterances,
ranging from major topic introductions to minor ones. While several SBEG
utterances embedded five levels or more are matched, others that are embedded
two levels or less are not.
Future Directions
A limitation of Arons' emphasis detection algorithm (as well as [Chen &
Withgott 1992] ) is that it does not determine the structure and the relationships
among the segments identified as salient. An analysis of the intonational
correlates of the discourse segmentation, like the one performed by [Grosz
& Hirschberg 1992] , could be performed with a focus on identifying
cues that distinguish the hierarchical structure. The ultimate goal would
be to determine whether it is feasible to "outline" speech recordings
using intonational and limited text-based analyses.[5]
Further research is needed in order to determine how to successfully combine
multiple cues to emphasis or structure. Many of the emphasis detection and
structure recognition algorithms described in this paper have focused on
a single linguistic cue (e.g., pitch range-- [Arons 1994b, Ayers 1994] ,
cue phrases alone, noun phrases alone, pauses alone-- [Passonneau &
Litman 1993] ). Grosz and Hirschberg have begun to investigate this problem,
attempting to predict the location of segment beginning and final utterances
from a series of intonational cues.
The discourse segmentation used in this study was performed by two experienced
labelers. A future experiment using naive[6]
subjects as segmenters and additional discourse samples is needed in order
to further validate these results.
Conclusion
This study compares the portions of a discourse identified as "salient"
by the Arons emphasis detection algorithm with the discourse structure as
defined by [Grosz & Sidner 1986] . Two main types of comparisons are
considered: one by segment category and the other by segment level. The
results show that the indices into the audio selected by the emphasis algorithm
correspond mostly to segment boundaries, in particular, segment beginnings
in the discourse structure. Since the algorithm primarily considers pitch
peaks, this corresponds to previous research findings that new topic introductions
(i.e., new segments) are associated with increases in pitch range.
The algorithm selects an equal number of segment beginning utterances at
several different levels of embedding rather than only the "outermost"
(i.e., least embedded) topics in the discourse. While there may be a relative
compression in pitch range as embedded segments are introduced, the least
embedded segments in the discourse do not necessarily correspond to the
absolute largest pitch ranges. Ayers' pitch tree algorithm [Ayers
1994] for locating segment boundaries uses relative differences in pitch
rather than absolute ones. Such an approach is an interesting alternative
to the one used by Arons. A combination of the two approaches may prove
useful for identifying segment beginnings and distinguishing them according
to their level of embeddedness in the discourse structure.
This project attempts to bring together research in the areas of summarizing
and skimming speech and discourse structure. The goal is to establish an
alternate approach to the problem of "speech summarization and skimming"
that is driven by the objectives of a real-world problem, yet has a principled
theoretical foundation as a basis for making claims.
Acknowledgements
Thanks to Barbara Grosz for providing direction, support, and helpful feedback
throughout this project. Thanks to Chris Schmandt for his support and encouragement.
Christine Nakatani segmented the discourse and gave valuable input. Barry
Arons assisted in the use of the emphasis algorithm. Michele Covell, Bill
Stasior, and Meg Withgott of Interval Research Corporation supplied the
discourse sample. Barbara Grosz, Christine Nakatani, and Barry Arons provided
feedback on the content of this paper.
References
Arons, B. Interactively Skimming Recorded Speech. Ph.D. Thesis. Massachusetts
Institute of Technology, 1994a.
Arons, B. Pitch-Based Emphasis Detection for Segmenting Speech Recordings.
In Proceedings of the International Conference on Spoken Language Processing,
pages 1931-1934. 1994b.
Ayers, G. Discourse Functions of Pitch Range in Spontaneous and Read Speech.
OSU Linguistics Deptartment Working Papers, vol. 44, 1994.
Chen, F. R. and Withgott, M. The Use of Emphasis to Automatically Summarize
Spoken Discourse. In Proceedings of the International Conference on Acoustics,
Speech, and Signal Processing, pages 229-233. IEEE, 1992.
Grosz, B. and Hirschberg, J. Some Intonational Characteristics of Discourse
Structure. In Proceedings of the International Conference on Spoken Language
Processing, pages 429-432. 1992.
Grosz, B. and Sidner, C. Attention, Intentions, and the Structure of Discourse.
Computational Linguistics, 12(3):175-204, 1986.
Hawley, M. J. Structure out of Sound. Ph.D. Thesis. Massachusetts Institute
of Technology, 1993.
Passonneau, R. J. and Litman, D. J. Intention-Based Segmentation: Human
Reliability and Correlation with Linguistic Cues. In Proceedings of the
31st Annual Meeting of the Association for Computational Linguistics. 1993.
Pierrehumbert, J. The Phonology and Phonetics of English Intonation. Ph.D.
Thesis. Massachusetts Institute of Technology, 1975.
Pierrehumbert, J. and Hirschberg, J. The Meaning of Intonational Contours
in the Interpretation of Discourse. In P. R. Cohen, J. Morgan and M. E.
Pollack, editors, Intentions in Communication, pages 271-311. The
MIT Press, 1990.
Silverman, K., Beckman, M., Pitrelli, J., Ostendorf, M., Wightman, C., Price,
P., Pierrehumbert, J. and Hirschberg, J. TOBI: A Standard for Labeling English
Prosody. In Proceedings of the International Conference on Spoken Language
Processing, pages 867-870. 1992.
Footnotes
1. Note that the sample has been slightly modified to remove personal identification.
2. If too many segments are selected (i.e., too many to allow enough time
savings) then the top scoring regions are selected for playback.
3. If the criteria are relaxed to allow indexes within two intonational
phrases, then the number of SBEGs selected increases to 18 out of 22 (82%)
and the number of segment boundaries to 21 out of 22 (95%).
4. Arons also wrote a pause-based algorithm using an adaptive pause detection
technique (see [Arons 1994a]) for finding segments following long pauses.
5. Limited because full-scale automatic speech-to-text transcription is
not practical; however, a technique such as keyword spotting might be applied
to locate cue phrases marking the discourse structure.
6. Subjects that are not familiar with discourse structure theory.