 |
||
 |
 |
|
|
Human Speechome Project The Human Speechome Project is an effort to observe and computationally model the longitudinal language development of a single child at an unprecedented scale. To achieve this, we are recording, storing, visualizing, and analyzing communication and behavior patterns in several hundred thousand hours of home video and speech recordings. The tools that are being developed for mining and learning from hundreds of terabytes of multimedia data offer the potential for breaking open new opportunities for a broad range of areas - from security to personal memory augmentation.
|
 |
Rumors in Social Networks: Detection, Verification and Intervention Motivated by the role that rumors played in the aftermath of the Boston Marathon bombings, we study the emergence, spread, and veracity of rumors in large, complex, and highly connected message passing systems such as social media platforms, with a particular focus on rumors surrounding emergencies. We are using the Boston Marathon bombings as a case study to develop computational models of rumors that can be used to predict the veracity, spread, and impact of rumors surrounding particular events. The end goal is to create an online rumor verification algorithm that can analyze rumors in real-time as events unfold. We hope our tool can be used by citizens, journalists, and emergency services to minimize the spread and impact of false information in social media during emergencies. |
|
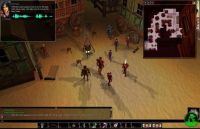
Interactive Data-Driven Simulation of Human Behavior and Language We are crowd-sourcing the creation of socially rich interactive characters by collecting data from thousands of people interacting and conversing in online multiplayer games, and mining recorded gameplay to extract patterns in language and behavior. The tools and algorithms we are developing allow non-experts to automate characters who can interact and converse with humans and with each other. The Restaurant Game recorded over 16,000 people playing the roles of customers and waitresses in a virtual resturant. Improviso is an effort to capture data from humans playing the roles of actors on the set of a low-budget sci-fi movie.
|
 |
HouseFly: Immersive Video Browsing and Data Visualization HouseFly combines audio-video recordings from multiple cameras and microphones to generate an interactive, 3D reconstruction of recorded events. Developed for use with the longitudinal recordings collected by the Human Speechome Project, this software enables the user to move freely throughout a virtual model of a home and to play back events at any time or speed. In addition to audio and video, the project explores how different kinds of data may be visualized in a virtual space, including speech transcripts, person tracking data, and retail transactions.
|
 |
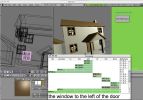
BlitzScribe: Speech Analysis for the Human Speechome Project BlitzScribe is a new approach to speech transcription driven by the demands of today's massive multimedia corpora. High-quality annotations are essential for indexing and analyzing many multimedia datasets; in particular, our study of language development for the Human Speechome Project depends on speech transcripts. Unfortunately, automatic speech transcription is inadequate for many natural speech recordings, and traditional approaches to manual transcription are extremely labor intensive and expensive. BlitzScribe uses a semi-automatic approach, combining human and machine effort to dramatically improve transcription speed. Automatic methods identify and segment speech in dense, multitrack audio recordings, allowing us to build streamlined user interfaces maximizing human productivity. The first version of BlitzScribe is already about 4-6 times faster than existing systems. We are exploring user-interface design, machine-learning and pattern-recognition techniques to build a human-machine collaborative system that will make massive transcription tasks feasible and affordable.
|
|
Speechome Recorder for the Study of Child Development Disorders Collection and analysis of dense, longitudinal observational data of child behavior in natural, ecologically valid, non-laboratory settings holds significant benefits for advancing the understanding of autism and other developmental disorders. We have developed the Speechome Recorder, a portable version of the embedded audio/video recording technology originally developed for the Human Speechome Project, to facilitate swift, cost-effective deployment in special-needs clinics and homes. Recording child behavior daily in these settings will enable us to study developmental trajectories of autistic children from infancy through early childhood, as well as atypical dynamics of social interaction as they evolve on a day-to-day basis. Its portability makes possible potentially large-scale comparative study of developmental milestones in both neurotypical and autistic children. Data-analysis tools developed in this research aim to reveal new insights toward early detection, provide more accurate assessments of context-specific behaviors for individualized treatment, and shed light on the enduring mysteries of autism.
|
 |
|
|
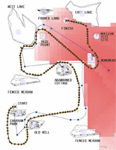
Semantic Spaces (2011) This project explores the connection between situated behavior and language use. Through the analysis of large amounts of video, it is possible to automatically partition a social space into it's semantically relevant pieces. Reinterpreting the video as sequences of activity in these discrete areas produces a representation of behavior that is simple and meaningful. These behavioral sequences can then be correlated to language transcripts to model the behavioral profiles of different words and phrases. It is even possible to predict which words will be spoken based on the activity in the video and vice versa. The final goal is to develop a series of methods to discover and represent the deep connection between behavior, context, communication and learning.
|
 |
Speechome Video for Retail Analysis (2011) We are adapting the video data collection and analysis technology derived from the Human Speechome Project for the retail sector through real-world deployments. We are developing strategies and tools for the analysis of dense, longitudinal video data to study behavior of and interaction between customers and employees in commercial retail settings. One key question in our study is how the architecture of a retail space affects customer activity and satisfaction, and what parameters in the design of a space are operant in this causal relationship.
|
 |
Learning Language using Virtual Game Context (2011) This project uses the gameplay data from The Restaurant Game and Improviso as linguistic corpora for automated language learning. These corpora are special because they include computer-interpretable non-linguistic context that contains cues as to what the players might mean with the words and sentences they utter. The results feed back into the original projects by contributing to the linguistic competence of the AI that is being developed for those games.
|
 |
Study of Child Language Acquisition in the Human Speechome Project (2011) What is the relationship between the input children hear and the words they acquire? We are investigating the role of variables such as input word frequency and prosody in one child's lexical acquisition using the Human Speechome Project corpus. We are analyzing data from ages nine to 24 months, including the child's first productive use of language at about 11 months, ending at the child's active use of a vocabulary with more than 500 words.
|
|
10,000x More Efficient Computing (2011) Varied important problems can be solved using surprisingly approximate arithmetic. We've designed a co-processor for such arithmetic that provides 100,000 cores on a single standard chip, or 1,000 cores in a sub-watt mobile device. We are exploring applications of such machines in image and video processing. Compared to CPUs, improvements in speed and energy use can exceed 10,000x.
|