|
The MIThril Inference Engine is an attempt to develop a simple, clean
architecture for applying statistical machine learning techniques to
the modeling and classification of body-worn sensor data. The
important design features of the system are simplicity, modularity,
flexibility, and implementability under tight resource constraints.
The MIThril inference engine exists as a collection of software tools.
The training side is implemented in MatLab and runs on desktop
hardware. (We have a Gaussian Mixture
Modeling Tutorial available online -- download the tutorial here
in tar.gz format or zip format.)
The modeling and classification side exists as a collection
of software tools that run in real-time on the MIThril hardware
platform -- see the inference
section of the MIThril CVS
repository
One of the first projects implemented using the MIThril inference
engine is an accelerometer-based motion classification system; for
more information see the
real-time motion classification project paper by Rich DeVaul and
Steve Dunn.
This page provides a simplified, non-technical overview of the
real-time modeling and classification side of the MIThril inference
engine. A more detailed and technical treatment is described in a
forthcoming white paper.
|
Architecture
|
|
|
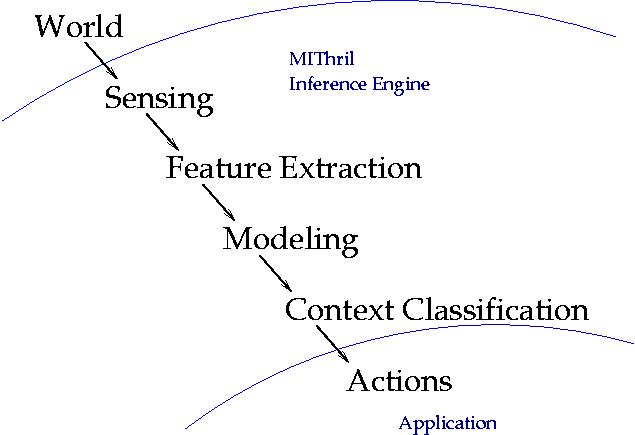
The MIThril Inference Engine architecture is divided into four distinct processes or levels:
- Sensing
- Feature Extraction
- Modeling
- Context Classification
The arrows in the diagram represent information flow, starting with
the "World" and ending with the application. At each level a distinct
operation is performed that facilitates the process of the next.
|
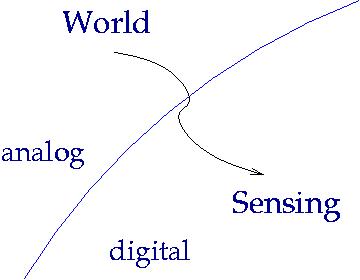
Sensing
The user's world is complex. The only things we can know
are what we measure thorough sensors or are explicitly told.
|
The process of measuring the "analog" world produces a sequence of
discrete "digital" observations. For any particular modeling task,
this digital signal contains some useful information and some
extraneous information.
For example, a three-axis accelerometer produces measurements that
combine "true" acceleration, some systematic bias, and some random
noise.
|
Feature Extraction
The first step in creating a model is deciding what features to use.
Features are "derived measurements" that extract model-specific
information from raw signals.

|
We can often simplify a modeling task by transforming raw observations
into a form that is more appropriate for a particular modeling task.
For example, features that use a pitch/energy representation might be
more appropriate for a speaker-identification modeling task than raw
audio samples.
|
Modeling
We use statistical machine learning techniques to create generative
and discriminative models. These models turn features into
probabilities or classifications.

|
For each context we want to model, a generative or discriminative
model is created. These models allow us to answer the question "which
state is the user in," or "how likely is state X?"
Our initial focus is creating simple Gaussian mixture models or SVM
classifiers, though more complex models (such as HMMs or hierarchical
mixture models) are also possible.
|
Context Classification
The context classification system provides the means to combine the
results of independent models and classifiers in a natural and
efficient way. These classifications are the output of the MIThril
Inference Engine.

|
Rarely will there be a one-to-one correspondence between the output of
a single model or classifier and an action to be taken. For
real-world applications, the description of context must be both
expressive and natural.
The context classification system allows "context rules" to be
specified in natural probabilistic language, such as "if it is a
weekday and it is after 5pm and it is very likely that I am leaving
the office, my action context is going home from work"
|
Actions
|
|
|
|
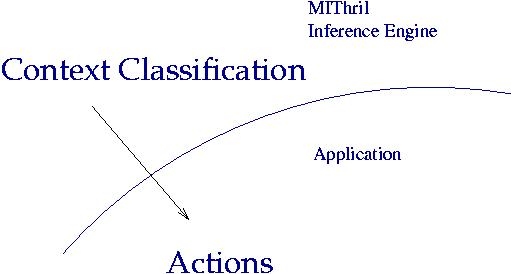
Action, or the result of context classification, is left up to the
application. However, applications may interact with the MIE by
creating new context classification rules, models, or features.
An important class of action is one that provokes a user interaction,
which in turn effects the user's state and hence the "world."
|
